





















While developing AI or ML models, most of the time and effort are often dedicated to data collection and model training. However, validation is equally important during model development because inadequate model validation may result in:
- Poor performance in real-world scenarios
- Incorrect or biased predictions, especially when faced with data outside the scope of the training set
- Overfitting or underfitting issues, where the model either memorizes the training data too closely or fails to capture its underlying patterns
Unfortunately, there’s no single validation technique that universally suits all machine learning models. Choosing the right validation method requires a nuanced understanding of both group and time-indexed data. In this post, we’ll dissect the primary validation methods and underscore why it’s crucial to rigorously test and validate the outcomes of your machine-learning model.
Data validation techniques for error and bias detection in AI training datasets
1. Single-batch validation
Bias in AI models can arise from biased training data, where certain groups are underrepresented or overrepresented, leading the model to learn and perpetuate these biases. Single batch validation is a method to quickly assess bias by evaluating the model’s performance on a small, randomly sampled batch of data during the data annotation process.
Here’s how the single-batch validation technique works:
Batch selection: During the training process, instead of evaluating the model’s performance on the entire dataset, a small random batch is selected for validation.
Demographic breakdown: The selected batch is then analyzed to ensure that it represents the diversity of the overall dataset. This includes checking the distribution of different demographic attributes such as gender, race, age, or any other relevant factor.
Performance evaluation: The model is evaluated on the selected batch, and its performance metrics are calculated. These metrics may include accuracy, precision, recall, F1 score, etc., depending on the nature of the task (e.g., classification, regression) that the AI model will perform.
Bias analysis: The performance metrics are compared across different demographic groups within the batch. Significant disparities in performance across groups may indicate potential bias in the model.
Iteration: This process is repeated periodically during training with randomly selected batches to get a more comprehensive understanding of the model’s behavior. By evaluating multiple batches, the assessment becomes more robust and helps in identifying consistent biases.
2. Cross-validation
It is a resampling technique commonly used in machine learning to assess the performance and generalizability of a model. It helps in providing a more accurate estimate of a model’s performance by partitioning the dataset into multiple subsets. Cross-validation is particularly useful when the dataset is limited or when there is a need to assess how well a model generalizes to new, unseen data. At the same time, this technique is computationally more expensive than holdout validation, as the model needs to be trained multiple times.
Here’s a basic explanation of the cross-validation process:
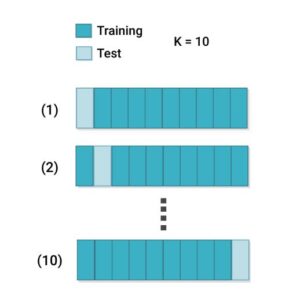
Data splitting: The dataset is segmented into “k” subsets, commonly known as folds. The most common choice for “k” is 5 or 10, but it can vary based on the size of the dataset and the specific needs of the analysis.
Training and testing iterations: The model undergoes “k” rounds of training and evaluation, where in each iteration, a distinct subset is utilized as the test set, while the remaining subsets are amalgamated to form the training set. In each iteration, the model is trained on a subset of the data and tested on the data that was not used for training.
Performance evaluation: After each iteration, the performance metrics are recorded. The final performance estimate is often the average of the performance metrics across all iterations.
Reducing variance: Cross-validation helps reduce the variance in performance estimates compared to a single train-test split. It provides a more robust assessment of a model’s ability to generalize to unseen data because it tests the model on multiple independent subsets of the dataset.
Types of cross-validation
1. K-fold cross-validation: The dataset is divided into “k” folds, and the model is trained and tested “k” times, each time using a different fold as the test set.
2. Stratified K-fold cross-validation: This is similar to K-fold, but it ensures that each fold maintains the same distribution of the target variable as the original dataset, addressing potential imbalances.
3. Leave-one-out cross-validation (LOOCV): Each data point is treated as a single fold, and the model is trained and tested “n” times, where “n” is the number of data points. LOOCV can be computationally expensive but is unbiased as it uses all available data for testing in each iteration.
3. Holdout validation
Holdout validation is a simple and common technique in machine learning for assessing the performance of a model. It involves splitting the dataset into two subsets: one for training the model and the other for evaluating its performance. The subset used for training is typically larger performance metrics that are averaged over the k iterations to obtain a more robust estimate of the model’s performance. Holdout data validation technique is particularly useful when you have a large dataset, and computational resources are limited.
Data splitting: The dataset is divided into two mutually exclusive subsets—typically, one for training and one for validation. The training set contains a majority of the data and is used to train the model, while the validation set is kept separate for assessing the model’s performance.
Training the model: The machine learning model is trained on the training set using a chosen algorithm. During training, the model learns patterns, relationships, and features from the input data.
Validation: Once the model is trained, it is evaluated on the validation set. The model makes predictions or classifications on the validation set, and its performance metrics are calculated. Common performance metrics include accuracy, precision, recall, F1 score, and others, depending on the nature of the problem.
Adjustments and iteration: Based on the performance of the validation set, adjustments to the model can be made. This may involve fine-tuning hyperparameters, modifying the model architecture, or addressing issues such as overfitting or underfitting. The process is iterated until a satisfactory model is achieved.
Final evaluation: After the model is tuned and finalized using the training and validation sets, a final evaluation is often performed on a separate test set that the model has never seen during training or validation.
4. Fairness-aware algorithm
These algorithms are designed to mitigate biases in AI models, ensuring that the predictions or decisions made by these models do not disproportionately affect certain groups. These algorithms aim to achieve fairness by carefully examining the data and adjusting the model’s behavior accordingly.
Here are some of the techniques to implement the algorithm:
Bias detection and measurement
Begin by identifying potential biases within the dataset. This involves assessing the distribution of data across different demographic groups and identifying any disparities.
Utilize metrics such as disparate impact, equalized odds, and demographic parity to quantify and measure the extent of bias.
Pre-processing techniques
Adjust the dataset to mitigate biases before training the model. This can involve techniques like re-sampling, re-weighting, or re-ranking data points to create a more balanced representation.
Implement techniques such as adversarial training, which involves training the model to be invariant to sensitive attributes, making it less likely to rely on them for predictions.
In-processing techniques
Modify the learning algorithm to account for fairness considerations during training. This may involve incorporating fairness constraints into the optimization process.
Use techniques like adversarial training, where an additional network is trained to predict the sensitive attribute, encouraging the primary model to be insensitive to these attributes.
Post-processing techniques
Assess and adjust model outputs after they have been generated to ensure fairness. This can involve re-ranking or re-scoring predictions based on fairness criteria.
Leverage re-weighting techniques to assign different weights to instances in the evaluation phase, ensuring fair assessments across different groups.
5. Random subsampling for model evaluation
Random subsampling, a common technique in machine learning, involves the random selection of subsets from a dataset. In this method, these randomly chosen subsets constitute the test set, while the remaining data is utilized for training the model. The process is typically repeated across multiple iterations, and the error rate is calculated by averaging the results obtained from each experiment.
In practice, when applying random subsampling, researchers and data scientists should carefully consider the nature of their dataset and the problem at hand. Additionally, for problems with imbalanced data, alternative techniques such as stratified sampling or other resampling methods may be preferred to ensure a more representative distribution in both training and testing sets.
Bottom line
Early detection of data errors and biases is crucial. Data errors can significantly impact the quality of the resulting model, even with sophisticated machine-learning algorithms. Moreover, predictions generated by these models are often logged and used to generate additional data for training. The techniques discussed in the post will help you make sure that your AI/ML models are built on a foundation of reliable and unbiased AI training data. Implementing these techniques demands extensive time and expertise, which can be availed easily by outsourcing data annotation services. This strategic approach not only saves valuable time but also results in error-free and unbiased AI/ML models.






{kind=link}